Mở Đầu
Hiện nay, YOLO (You only look one) trở thành 1 trong những model series tốt nhất cho Computer Vision (CV).
Với 1 người mới bắt đầu nghiên cứu về Artifical Intelligence (AI), ghi lại những gì đã tìm hiểu được dưới dạng Blog có lẽ là 1 ý tưởng hay
Để tìm hiểu rõ cấu trúc cũng như những suy nghĩ tinh túy đằng sau các phương trình, hãy thử bắt đầu từ những dạng đầu tiên theo thời gian
One-stage detectors - Two-stage detectors
- Two-stage detectors: gồm 2 bước (giai đoạn)
+ Detection: xác định object



- One-stage detectors: Không phân các bước rõ ràng mà cùng lúc thực hiện bounding box và classification
YOLO là tiêu biểu của dạng One-stage detectors, vì vậy mà có cái tên You Only Look Once
So sánh one-stage và two-stage detection
- One-stage dùng cùng 1 model cho cả 2 bước trong khi two-stage dùng 2 model khác nhau
- Do cấu tạo khác nhau ảnh hưởng đến tốc độ tính toán và đặc điểm hội tụ, Two-stage detectors thườngcó độ chính xác cao hơn nhưng chậm hơn one-stage detectors

YOLOv1
Là 1 mạng CNN gồm 24 lớp:
- 1 lớp Reduction layer (1x1) để giảm kích thước ảnh
- Các lớp chập Convolution layers (3x3)
- Các lớp Max pooling để giảm bớt độ nặng 1 cách nhanh chóng
- 2 lớp cuối Fully Connected Layer quyết định class của item
Là 1 model đã train sẵn và không thể đào tạo hay chỉnh sửa thêm, chỉ có lấy ra dùng, được tích hợp nhiều model nổi tiêng sdanhf riêng cho Computer Vision

Vậy YOLO hoạt động như nào?
Phương thức xác định

Đầu tiên chia 1 bức ảnh thành SxS ô grid cell (thường S =7 để không quá nhiều tham số)
Nếu trọng tâm của 1 vật thể nằm trong 1 ô grid cell nào đó, thì ô đó sẽ chịu trách nhiệm xác định vậy thể đó
Ô lưới sẽ đưa ra 2xB+C dự đoán cho vật thể ( B bounding box và C classes, với YOLOv1 thì mặc định B = 2 và C=20):
- Với mỗi B bounding box, có thêm 5 giá trị param là: x (tung độ của trọng tâm so với grid cell), y (hoành độ của trọng tâm so với grid cell), w (width, độ rộng của trọng tâm so với toàn bức ảnh), h (height, độ cao của trọng tâm sao với toàn bức ảnh) và confidence (xác suất đó là vât thể cần tìm)

Từ 2 bounding box, ta dựa vào confidence và IOU (Intersection over Union, giao tập hợp) so với Ground truth box (bounding box được gán bằng tay trích xuất từ các label app)m cả 2 đều chọn thông số lớn hơn
- Đối với Yolov1, C =20 và sẽ có 20 giá trị xác xuất cho 20 classes. Sau đó dựa vào hàm Softmax để lựa chọn class phù hợp với bounding box


- Vế đầu tiên và vế thứ hai là Localization loss.
- Vế thứ ba và bốn là Confidence loss.
- Vế cuối cùng là Classification loss.
luôn bằng 1 còn của bounding box thuộc cell .
- Thành phần thứ hai là phần loss cho trường hợp cell không chứa objet:
Cij luôn bằng 0 còn của bounding box thuộc cell .
nếu box thứ của cell thứ không chứa object.
- Cùng nhìn vào object loss, do trong ảnh đa số các grid cell không chứa object nên nếu để , việc này có thể ảnh hưởng đến độ chính xác của model. Vì vậy ở đây lấy .
Classification loss
Lcls=i=0∑S21iobjc∈classes∑(pi(c)−p^i(c))2
nếu cell thứ chứa object (chỉ tính classification class khi biết trong cell có chứa object).
(được tính chung cho cả grid cell)
Quá trình training
- Pretrain 20 Conv layers đầu + Avarage Pooling layer + FC layer trên tập dữ liệu ImageNet khoảng 1 tuần để đạt được top-5 accuracy khoảng 88%. Ảnh đầu vào có kích thước 224x244. Sử dụng Avarage Pooling có độ chính xác cao hơn Max Pôling
- Chuyển model để thực hiện detection. Để làm điều đó thì giữ lại 20 Conv layers bên trên thêm vào 4 Conv layers + 2 FC layers với khởi tạo ngẫu nhiên weights. Ảnh đầu vào được đổi thành 448x448 để thuận tiện cho việc minh họa. Sau đó phần sau được train trên bộ dữ liệu PASCAL VOC.
- Một số hyperparameters:
+ epochs = 135
+ batch_size = 64
+ momemtum = 0.9
+ decay = 0.0005
+ learning rate = [10-2, 10-3, 10-4]
+ dropout = 0.5
+ augmentation = [scaling, translation, exposure, satuaration]
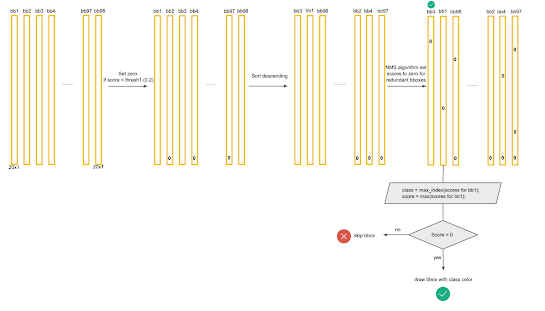
Non-Max Suppression (NMS)
Như đã nói, tồn tại các trương hợp mà vật thể quá lớn so với ánh rvaf phán ddooans trọng tâm có thể rời vào nhiều grid cell dẫn đến vật thể có thể bị dự đoán nhiều lần. NMS là 1 cách xử lí vấn đề này:
- Loại bỏ những đối tượng có confidence C < Threshold ( ngưỡng này chúng ta có thể re-setup).
- Sắp xếp những đối tượng có confidence C theo thứ tự giảm dần.
- Chọn bounding box của những vật thể có confidence C cao nhất và xuất ra kết quả.
- Loại bỏ những bounding box có IOU < IOU-threshold (ngưỡng này chúng ta có thể re setup)
- Quay lại bước 3 cho tới khi mọi kết quả được kiểm tra.
Để nói rõ hơn
Pr(classi∣object)⋅Pr(object)⋅IOUpredtruth=Pr(classi)⋅IOUpredtruth
Tương ứng với mỗi bounding box chúng ta sẽ có 20 giá trị thể hiện score của từng class trong bounding box. Tổng cộng có 98x20=1960 giá trị

Một số so sánh
 |
| mAP and FPS Results (VOC 2007) |
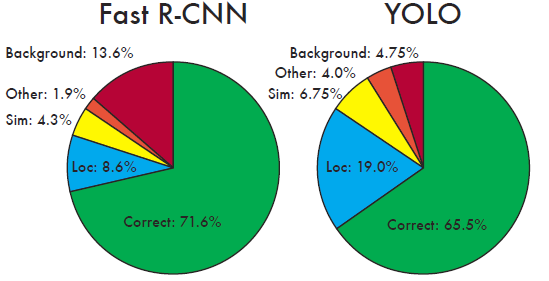 |
| Error Analysis (VOC 2007) |
 |
| Fast R-CNN + YOLO (VOC 2012) |
 |
| Generalization Results |
Implement
Với model hỗ trợ là VGG16
https://github.com/ezrafield/mlai-read-rewrite/blob/main/yolov1-rewrite.ipynb
Nhận xét
Đăng nhận xét