MagicPoint + CNN (VGG16) + Homography + Loss (keypoint loss + descriptor loss) = Superpoint
Superpoint + GNN(Graph Neural Network) = SuperGlue
https://github.com/magicleap/SuperGluePretrainedNetwork
- SuperGlue + Transformer = LoFTR (Detector-Free Local Feature Matching with Transformers)
https://zju3dv.github.io/loftr/
- sequence to sequence matching perpestive + LoTTR= STTR -> Stereo depth estimation ?
sequence: HMM (Hidden Markov Models)
HMM + SVM(Support Vector Machine) = Fisher Kernel
Edge Detector + Hessian matrix + PCA( principal component analysis) = Harris Corner Detector
Edge Detector (ý tưởng) + DOG (Difference of Gaussian) = Pyramid Image Preprocessing
(Scale-Invariant + Pyramid) (keypoint) + HoG (Histogram of Gradient) (descriptor) = SIFT
(Scale-Invariant + Hessian matrix + Gaussian Kernel + Pyramid) (keypoint) + HaarWavelet (descriptor) = SURF
- Epipolar Geometry + Camera Pose = MSV (Multi-Stereo View )
SIFT + ... = VLAD ?
Fisher Kernel ngang hàng VLAD
VLAD + ... = NetVLAD ?
Scale-Invariant -> Feature Extraction + Descriptor matching (Euclide Distance L1-Norm)
- Gipuma
NMS (Non-maximal Supression)
CNN(VGG16) + Boundingbox +IOU (Intersection over Union) +Loss (Localization + Confidence + Classification) = Yolo1 ( S*S*(5*B+C)) (1 object/ 1 gridcell)
CNN(Darknet19) + Yolo1 (ý tưởng) + Archonbox (từ FastRCNN) + BatchNorm layer = Yolo2 (S*S*B*(4+1+C)) ( nhiều object/ 1 gridcell)
Low-level Vision
1. Kernel
1.1. Sobel
Thay thế đạo hàm/ Gradient
Chạy với Convolution Layer


1.1. Gaussian
Mục đích làm feature trải đều hơn trên 1 khu vực -> tiến đến phân phối chuẩn (Normal Rule),


2. Dimension Reduce
2.1. PCA - Principle Componant Analysis
- Giảm chiều dữ liệu
Giúp xác định Feature chính
- Bất lợi: Mất khá nhiều feature
- Thuật toán core: Covariance Matrix + Chéo hóa matrix ( Diagonalizable matrix)
2.2. LDA - Linear Discriminant Analysis
Khái quát của Fisher 's Linear Discriminant
gần ANOVA model
Mục đích chính cũng là tìm mô tả tốt nhất cho tập data


3. Structure
https://www.mathworks.com/help/deeplearning/ref/deepnetworkdesigner-app.html
3.1. Pyramid
- https://en.wikipedia.org/wiki/Pyramid_(image_processing)
- Khá giống mô hình NN (trừ mjucj đích không phải train qua lại để tối ưu parameter mà để thực hiện phép tính)
- mục đích: encode hoặc decode
- Sử dụng: thường đi theo image processing theo dạng thay đổi scale
- Hay chạy cùng Gaussian Kernel + biến đổi scale (/2 như SIFT hoặc +2 như SURF)

3.2. MagicPoint
- Định nghĩa bởi MagicLeap
Đơn giản là 1 neural network sau khi được train qua tập các hình học cơ bản (cả 2D và 3D) (ví dụ Synthetic Shape Data) đã được label
- Tập data này có thể đựa tạo bởi những hàm trong OpenCV
- Sử dụng để làm khuôn cho Superpoint
- Sử dụng trong keypoint detector

- https://github.com/rpautrat/SuperPoint/blob/master/superpoint/datasets/synthetic_dataset.py
3.3. Visual Geometry Group VGG
- 1 CNN được ứng dụng khá nhiều nổi tiếng bởi tính đơn giản
- input: 224x224
- Ứng dụng nhiều trong classificate đơn giản hoặc làm baseline cho model phức tạp
- https://keras.io/api/applications/vgg/


3.4. Unet
Tên thế vì giống hình chữ U. Là kiến trúc được sử dụng nhiều trong bài toán image-to-image. Có điểm tương tự với kiến trúc Encoder-Decoder đối xứng, được thêm các skip connection từ Encode sang Decode tương ứng. Về cơ bản, các layer càng cao càng trích suất thông tin ở mực trừu tượng cao, tức các thông tin mức trừu tượng thấp nhưu đương nét, màu sắc, bộ phận, độ phân giải, ... sẽ mất đi trong lúc lan truyền nên có thêm skip-connected để giải quyết vấn đề
Với Encode, feature-map được downscale bằng các Convolution. Ngược lại ở decoder, feature- map để upsale bới upsampling player

3.5. Residual Network ResNet
- Được tạo ra với mục đích giải quyết Vanishing Gradient
- Cấu trúc có thêm lớp Residual Block

- code https://d2l.aivivn.com/chapter_convolutional-modern/resnet_vn.html
3.6. Coordinations
Là những hệ tọa độ cơ sở, những object cần tập trung, xây dựng nên các bài toán của Computer Vision và Camera Vision.
- World Coordination: hệ tọa độ tại thế giới thực / không gian đang xét tương đồng
- Sensor Coordination: Biểu diễn vị trí và các hướng của object
- Camera Coordination: hệ tọa độ camera
- Image Coordination: hệ toạ độ biểu diễn hình chiếu của 3D structure trên image
world - sensor : 1 rotate + 1 translate
sensor - camera: extrinsic (1 rotate + 1 translate)
camera - image: intrinsic ( priciple point, distance, facos function, 1 rotate + 1 translate + 1 scale)
3.7. Attention
https://viblo.asia/p/tim-hieu-ve-co-che-attention-924lJjbmlPM
Mục đích để có thể focus vòa một vài phần nào đó của input trong quá trình processing thay vì chú ý toàn bộ
Algorithm:
- input -> 1 network trong khi 1 phần khác của input đi qua 1 network khác
- netword cho weight vào mỗi neuron, cho attention vào part đó của input
- tổng hợp lại để tạo output, Là tổng weights ở Neurons, với weights miêu tả attention của mỗi part của input
-output qua layer mới hoặc làm final output
https://en.wikipedia.org/wiki/Attention_(machine_learning)



Ví dụ sắp xếp lại thứ tự từ ngữ khi dịch tiếng Anh sang tiếng Pháp

Mathematic
1. Matrix
1.1. Hessian matrix
dạng covariance đạo hàm / gradient của các dimension

1.2. Covariance matrix
Là matrix n x n thể hiện mối tương quan của các dimension (n-D)
cov = 0 <=> independent
Rất quan trọng trong nghiên cứu các ML Model, đặc biệt là dạng Linear

1.3. Bicubic interpolation
Dự đoán các pixel dựa vào các pixel xung quanh. Ý tưởng khá giống xử lí null value trong Recommend System

Có 3 dạng cách chính:
- Neighbour: dựa vào value giá trị gần nhất
- Linear: dựa vào đường nối 2 điểm cạnh bên
- Cubic: giống việc tìm nguyên hàm
1.4. Distortion


2.1. Diagonalizable matrix
Chéo hóa ma trận

- Ứng dụng rất nhiều
- Ví dụ trong tìm constaint / invariant trong các algorithm
- https://vi.wikipedia.org/wiki/Ma_tr%E1%BA%ADn_ch%C3%A9o_h%C3%B3a_%C4%91%C6%B0%E1%BB%A3c
- Nếu trong trường hợp không phải matrix vuông => C = UT DV
2.2. Difference of Gaussian DOG
- Tính distance giữa các lớp Gaussian của các layer scale liên tiếp (scale khác nhau)
- Mục đích: xác định keypoint nổi bật bởi sự thay đổi đột ngột giá trị tại khi qua các layer
- Bất lợi: dựa vào 1 feature cố định
- Ví dụ: dùng trong SIFT để xác định scale-invariant

2.3. Histogram of Gradient
- Kết hợp 1 method với độ gần xa của các pixel
- Mục đích: Xác định góc, độ lớn của mô tả vector descriptor
- Ví dụ: dùng trong SIFT
- Nên xác định trước chia bao nhiêu góc, độ rộng bao nhiêu

- Trong bài toán Keypoint Descriptor, dễ dẫn đến các match sai/ Outliners Matches vì hệ thống lại mô tả keypoint 1 cách đơn giản
2.4. Homography
Là kĩ thuật biến đổi 1 không gian tọa độ dựa theo bức ảnh này trở thành không gian tọa độ dựa theo bức ảnh khác
Được biểu diễn dưới dạng 3x3 là matrix hợp của 1 phép tính tiến + 1 phép quay 3D + 1 phép scaling (3/4 phép biến đổi affine cơ bản, không có nghịch đảo)
u = T R v

2.5. Maximal Likelihood Estimate MLE
Likelihood: là 1 trị số cho thấy khả năng model fit với observed data (thường là giá trị xác xuất)
MLE Là 1 phương pháp tìm tham số để maximize likelihood function
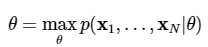
Ví dụ: https://viblo.asia/p/so-luoc-ve-maximum-likelihood-estimation-1Je5EvrYKnL
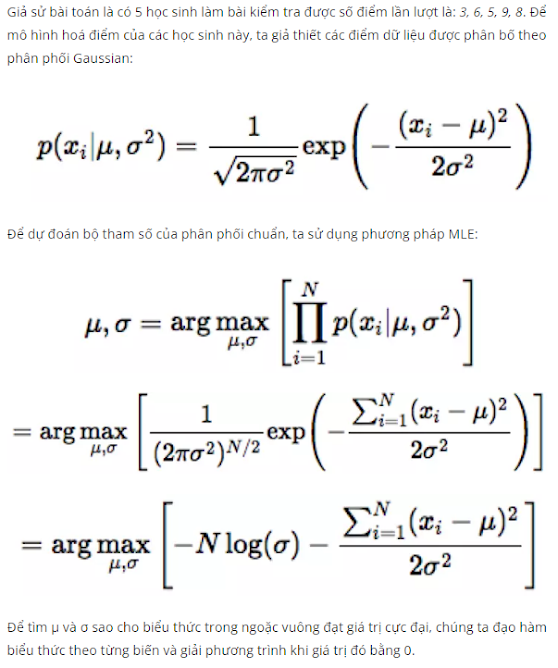

Log-likelihood: là logarit của likelihood chỉ để dễ tính hơn, MLE thì vẫn vậy
Cross Entropy loss: là trị số đo sự khác nhau giữa 2 phân phối (mô hình) trong việc training classifier. Là trung bình âm của log-likelihood của true class.
Minimize cross-entropy loss = maximizing likelihood
3. Space
Với Computer Vision, ta sẽ hay nói về topological space là chính
Tức là 1 cấu trúc toán học tổ hợp 1 tập point và 1 tập các quy tắc (gọi là topology) để xác định tính "đóng" và "gần" đến tập khác -> dùng để mô tả cấu trúc của 1 space
1 topological space là 1 tập các tập mà chứa mọi points "đóng" đến given points. Tức đóng với hữu hạn intersection và union. Topology là 1 cách encoding inforrmation về relationship giữa các points
3.1. Compact space
Là 1 topological space "đóng" và "có giới hạn/bị chặn". Tức mọi cover mở có hữu hạn subcover, mọi infinite sequence (chuỗi vô hạn) có 1 coverging subsequence (chuỗi con hội tụ)
Thường dùng với continous function (hàm liên tục) cũng như nghiên cứu convergence of sequences and series (sự hội tụ của chuỗi)
3.2. Metric space
Là topological space có thêm cấu trúc metric. 1 metric là 1 hàm định nghĩa khoảng cách giữa 2 points ( có các tính chất: không âm, symmetric, thỏa mãn triangle inquality (bất đẳng thức tam giác)) -> "closeness" hơn là "nearness"(hèn gì close với near đồng nghĩa :v )
Thường dùng để định nghĩa convergence, completeness và compactness
3.3. Euclidean space
Là 1 metric space tập trung vào khoảng cách các points
Ví dụ: 3D, 2D, ...
-> Khoảng cách vector là khác :v
3.4. Hibert space
Là 1 loại không gian vector vô hạn chiều (infinite-dimensional vector space) mà có inner product (dot product) giữa các vector. Inner product được dùng để định nghĩa length (chiều dài) và angle (góc) giữa các vector
Hibert spaces là comlete, tức mọi Cauchy squence of vectors (chuỗi Cauchy) hội tụ tại 1 điểm cũng trong space (key feature của Hibert space)



Matching pairs
1. Only keypoint
1.1. Harris Corner Detector
- Xác định các góc trong ảnh
- Thuật toán core: Hessian matrix + PCA
- Bất lợi:
+ Trong bài toán xác định keypoint, chỉ xác định được các góc, không phù hợp tìm tất cả keypoint
+ Không có Descriptor, chỉ có Coordination -> Không dùng để matching

2. +Descriptor
2.1. SIFT
Scale-invariant feature transform
- Tìm và nối keypoints
- Tập trung vào Scale-invariant
- Thuật toán Core: Difference of Gaussian DoG + Pyramid + HoG
(Scale-Invariant + Pyramid) (keypoint) + HoG (Histogram of Gradient) (descriptor) = SIFT
- output : keypoint set (index-vector)+ descriptor (128-D)
- Bất lợi: dùng Pyramid với DoG nên phụ thuộc feature màu lớn -> Accuracy yêu trong trường hợp thay đổi góc sáng ( càng tối các màu càng đen khó phân biệt)
- Thường là nguồn cho các model theo hướng model-centric (VLAD, COLMAP, ... )
- Tự code: https://github.com/ezrafield/ibm-certificate-final/blob/main/find_matrix_rotate_by_SIFT_class.ipynb
2.2. SURF
Speeded-Up Robust Feature
- Thuật toán gần như tương tự SIFT
- Tốt hơn SIFT về mặt thời gian nhưng descriptor và cách chọn keypoint có phần đơn giản hơn
- Sử dụng Hessian Matrix + Gaussian kernel làm nền:


- Tại Descriptor, sử dụng tọa độ Haar-Wavelet
- code: https://github.com/deepanshut041/feature-detection/tree/master/surf
- hyper parameter thêm chỉ có scale
- output cũng là 128-D
2.3. Superpoint (2018)
Self-Supervised Interest Point
- Là dạng data-centric cho xác định keypoints + descriptor
- Mục đích chính: Tạo 1 dataset để train NN mà không cần label bằng tay

3 bước:
- Interest point pre-training: Synthetic Shape Data -> MagicPoint
- Interest point Self-labeling: COCO+ HA (Homography Adaptation) + Base Detector -> Self-labeled dataset

- Joint Training: Self-labeled dataset -> Superpoint Model
- Arxiv 2018: https://arxiv.org/pdf/1712.07629.pdf
- Code: https://github.com/rpautrat/SuperPoint
- MagicLeap: https://github.com/magicleap/SuperPointPretrainedNetwork
- Tự code + so sánh SIFT: https://github.com/ezrafield/ibm-certificate-final/blob/main/superpoint.ipynb
- Do dựa vào data nên lợi thế là cải thiện các false matchs từ việc chọn feature của model-centric, nhưng cũng gây bất lợi là khó hiểu, khó chỉnh nếu có lỗi
- Có khả năng chỉ so sánh 1 phần image nếu có thể xác định đó là phần chính (tụ nhiều keypoint), SIFT phải so sánh toàn ảnh
- output là 256-D
- Structure VGG với 1 encode 2 decode (1 cho keypoint detector, 1 cho descriptor) class output là probability của "point-ness"
- Loss function: keypoint loss + descriptor loss
3. Matching method
3.1. Euclide distance L1-Norm
Áp dụng Brute Force để tìm ra các cặp pair có khoảng cách vector nhỏ nhất (theo Euclide distance)
- Với mỗi vector trong set A, thường chọn 1 vector trong set B có khoảng cách nhỏ nhất + 1 vector trong set B có khoảng cách nhỏ nhì làm dự bị
- Dạng L1-Norm
- Sử dụng được với các vector Descriptor có tính independent

Camera Pose Estimate - Structure from Motivation
1. Mathematic
1.1. Intrinsic
- Là mô tả chuyển đổi giữa tọa độ ảnh và tọa độ camera
- matrix 3x3

p là principal point (giao giữa Oz và Image) và f là hàm biến đổi



Có thể viết thành P = K [R t]
Với nhớ lại u = R t v trong homography
Vậy muốn tính được Intrinsic khi có Rotate, translate và homography
https://hoanglong187.blogspot.com/2022/09/6-sift-part-4-homographies-camera-models.html
Nếu ta biểu diễn image theo dạng X = d + alpha.a + beta.b (a, b là 2 vector gốc của tọa độ image 1)
Mục đích ta là tìm ma trận T biến A thành B



1.2. Extrinsic
- Là mô tả chuyển đổi giữa tọa độ camera và tọa độ world
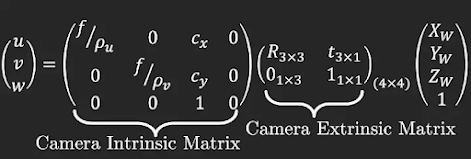
Vậy nếu muốn tính Extrinsic ta phải dựa vào Intrinsic và 2 tọa độ
1.3. Epipolar Geometry
- Để xác định vị trí của 1 điểm 3D dựa vào 2 image có hình chiếu của ảnh

Có 2 trường hợp là Paralled Calibrate Camera và Generate Case
- Với Paralled, ta có thể dễ dàng tính toán dựa trên định lí Talet trong hình học phẳng. Ứng dụng thường là kết hợp CNN để tính motivate
- Với Generate Case, ta định nghĩa Fundamental Matrix F




1.4. Triangulation
- Là xác định tọa độ 3D của điểm dựa vào hình chiếu tại >= 2 images
Thường phương pháp hay sử dụng là dùng Essential Matrix, với:


https://en.wikipedia.org/wiki/Trifocal_tensor
- Thường dùng với Trifocal Tensor để xây dựng graph với các iamge là node, các edge là matching pair với việc thêm các node mới có 2 trạng thái uncalibrated ( không biết intrinsic và extrinsic) và calibrated (biết intrinsic và extrinsic) với hỗ trợ của RANSAC và PnP
2. Camera calibration
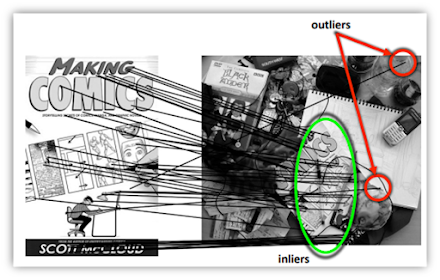
2.1. RANdom SAmple Consensus RANSAC
Dùng để estimate 1 model từ data chứa outliers
Algorithm:
- Chọn random 1 subset
- Check xem có bao nhiêu outliers với mean squared error MSE hoặc absolute error AE
- Đặt 1 threshold, nếu cao hơn thì good fit, nếu thấp hơn thì chọn random lại subset khác
Cơ sở toán học là lấy mẫu random để ước tính phân phối
- Có thể dùng để tính homography
2.2. Perpestive n Points PnP
Dùng để estimate extrinsic
Sử dụng Levenberg-Marquardt algorithm hoặc Gauss-Newton algorithm
Extrinsic là 3x4 matrix

(P0P: 6 DOFs, P1P: 4 DOFs, P2P: 2 DOFs, P3P: 0 DOFs)
Nhưng lại có đến 8 solutions -> cần ít nhất 4 cặp -> lí do có P4P
Càng nhiều matches hơn là để tối ưu trong trường hợp false match
3D Reconstruct
1. Bundle Adjustment BA
Thường là bước cuối của 3D-reconstruction dạng feature-base






Nhận xét
Đăng nhận xét