Mở đầu
Với Transformer, có 2 mô hình nổi tiếng nhất là BERT và GPT. Nay ta đi tìm hiểu xem GPT có gì, thay đổi gì qua các phiên bản
Improving Language Understanding by Generative Pre-training (GPT-1 2018)
GPT là viết tắt của Generative Pre-training của 1 language model trên 1 kho văn bản phân kì (diverse corpus) không được gán nhãn, sử dụng discriminative fine-tuning cho mỗi task đặc thù. Tức thay vì như trước đây, ta giờ dùng task-aware input transformations trong khi fine-tuning để có thay đổi ít nhất cho kiến trúc mô hình. Và được cải thiện dựa trên những SOTA của các task -> 1 mô hình chung nhất xử lí mọi task
Trong NLP, khả năng học từ raw text rất quan trọng để giảm bớt sự phụ thuộc supervised learning.
Vấn đề 1: khan hiếm tài nguyên dữ liệu dán nhãn , hạn chế áp dụng nhiều task. Hơn nữa, chưa chắc việc được biểu diễn theo supervised tốt hơn unsupervised
Vấn đề 2: việc tận dụng nhiều thông tin word-level từ unlabeled text, có 2 thách thức:
- Không rõ loại mục tiêu tối ưu hóa nào phù hợp cho việc chuyển giao đến text representations. Với từng task lại có loại phương pháp riêng (language modeling, machine translation. discourse coherence)
- Không có sự đồng thuận về biểu diễn đã học với target task. Các task-specific changes đến cấu trúc model như intricate learning schemes và adding auxiliary learning objectives
-> khó phát triển phương pháp bán giám sát (semi-supervised) cho language processing
=> Cách tiếp cận semi-supervised cho language understanding tasks là sự kết hợp unsupervised pre-training và supervised fine-tuning.
Mục tiêu là tìm 1 phổ quát thích ứng được 1 loạt các tasks, được đào tạo từ lượng lớn dữ liệu không nhất thiết cùng miền
Ta sử dụng two-stage training procedure:
- Mô hình hóa unlabeled data để học initial parameters của 1 neural network model
- Điều chỉnh parameters cho target task bằng supervised objective tương ứng
Sử dụng Transformer làm core vì tính chất long-term memory dependencies in text. Học qua 4 loại language understanding tasks: natural language inference, question answering, semantic similarity và text classification
1. Related work
Semi-supervised learning for NLP: Các phương án sớm nhất được sử dụng cho unlabeled data là word-level và phrase-level, mà được dùng như features cho supervised model. Các năm gần đây, word embeddings, được train từ unlabeled corpus cải thiện đáng kể các tasks. Tuy nhiên, vẫn chủ yếu trong chuyển đổi word-level, trong khi ta cần higher-level semantics
-> Phrase-level hoặc sentence-level embedding, có thể train bằng unlabeled corpus, được xử dụng để encode text về vector phù hợp cho nhiều tasks khác nhau
Unsupervised pre-training: là 1 case đặc biệt của semi-supervised learning với mục đích là tìm good initialization point thay cho supervised learning objective. Nhiều nghiên cứu chỉ ra rằng, pre-training như 1 regularization scheme cho phép khái quát hóa (generalization) trong deep neural network.
Phương pháp pre-training dùng language modeling objective (LSTM) rồi fine-tuning về target task với supervision có hạn chế về short range. Trong khi transformer networks có range dài hơn. Cách tiếp cận khác là hidden representations từ 1 pre-trained language hoặc machine translation model như auxiliary features khi training supervised model trong target task lại có hạn chế là tạo quá nhiều parameters mới cho 1 target task riêng lẻ
Auxiliary training objectives (đào tạo phụ trợ): là 1 dạng alternative way của semi-supervised learning (ví dụ POS tagging, chunking, named entity recognition, and language modeling để cải thiện semantic role labeling). Tuy nhiên, unsupervised pre-training đã học một số khái cạnh ngôn ngữ liên quan target tasks.
2. Framework
Quá trình training được chia làm 2 stage:
- Học high-capacity language model trên large corpus của text
- Fine-tuning stage, thích nghi model với discriminative task với labeled data
2.1 Unsupervised pre-training:

2.2 Supervised fine-tuning:
Ta cần tinh chỉnh parameters đến supervised target task.

Ta nhắc lại 3 loss tại model Yolov1: loss confidence + loss classificate + loss coordination, với Transformers, ta gom loss coordination vào loss confidence. Vậy nhìn chung, mục đích của ta chỉ để minimize (maximize likelihood) bài toán tổng tuyến tính có trọng số của 3 loss (likelihood) này.

Việc xử lí từng task-specific giờ chỉ cần chú ý vào cách tokenization và sử dụng song song architect (mã hóa input tương ứng):
Text entailment: concat premise p và hypothesis h token sequence, ngăn cách bởi <SEP> ($) token
Similarity: Vì không có thứ tự giữa 2 sentences. Vậy ta chỉnh thành so sánh tất cả các thứ tự khả thi independent (song song) rồi lấy linear output layer
Question Answering and Commonsense Reasoning: ta có context document z, question q, và tập answers {ak}. Ta concat thành [z;q;<SEP>;ak] như 1 sequence input xử lí song song (independent) sau đó normalized và softmax layer
3. Experiments
3.1. Setup
Unsupervised pre-training: BooksCorpus dataset chứa 7000 sách hoặc alternative dataset 1B Word Benchmark (ELMo) -> model ổn với sentence level -destroying long-range structure (tiến tới word-level dictionary semantic: thực sự hiểu nghĩa từ như xây dựng ngôn ngữ thật)
ELMo mắc lỗi sơ đẳng là shuffle ở mức câu với dataset book, làm mất đi tính phụ thuộc của long-range, vì với sách nó gần như liền mạnh từ đầu tới cuối, nhất là trong cùng 1 chương. Với GPT họ giữ nguyên nên họ đạt very low token level perplexity (pp càng thấp càng tốt)
Model specifications:
- 12-layer decoder-only transformer with masked self-attention head (768 dimension states, 12 attention heads)
- Position-wise feed-forward networks: 3072-dimensional inner states
- Adam optimization, max learning rate = 2.5e-4 (increased from 0 to 2000 and annealed to 0 by cosine schedule)
- 100 epochs minibatches of 64 randomly sampled, contiguous sequences of 512 tokens
- Layer Norm: N(0,0.02)
- bytepair encoding (BPE) vocabulary 40000 merges, 0.1 rate regulazitation (residual, embedding, attention dropout)
- L2 regularization : w = 0.01 trên mọi bias hoặc gain weights.
- Activation function: Gaussian Error Linear Unit (GELU)
- learned position embeddings thay vì sinusoidal version
- fifty library cho raw text trong BooksCorpus, standardize punctuation và whitespace, dùng spaCy tokenizer
Fine-tuning details: Giữ lại của unsupervised pre-training, chỉ thay đổi 1 ít. Dropout for classifier: 0.1. Learning rate 6.25e-5, batchsize 32.Thường finetunes nhanh nên 3 epochs training. Linear learning rate decay với 0.2% training, lambda = 0.5
Language Models are Unsupervised Multitask Learners (GPT-2 2019)
Cải tiến chủ yêu của GPT-2 là sử dụng dataset lớn hơn, mô hình nhiều tham số hơn. Thường hàm mục tiêu là dạng P(output|input) nhưng ở GPT-2 là P(output|input, task) (task conditioning) -> Output khác nhau với các nhiệm vụ khác nhau từ cùng một input
Số tham số: 117m (giống GPT-1) , 345m -> 762m -> 1.5B (GPT-2)
Mục đích: xây dựng general system có thể làm nhiều tasks, kể cả không cần thường xuyên tạo hay label 1 raning dataset cho mỗi task
Byte Pair Encoding (BPE) + Bloom filters + n_gram
Approach
Ta có tập examples (x1, x2, ..., xn) và variable lenghth sequences of sympbols (s1, s2, ..., sn)

Với 1 language model (LM) với tập dữ liệu càng lớn, ta cần 1 cách embedding thích hợp, nhất là khi xuất hiện của out-of-vocabulary, byte-level (UTF-8) được nghiên cứu nhưng không cạnh tranh được word-level trong LMs on large datasets (1 billion word benchmark)
Byte Pair Encoding (BPE) là 1 cầu nối giữa character và word level language modeling mà có hiệu quả nội suy giữa word level inputs cho các chuỗi kí tự thường xuyên và character level inputs cho các chuỗi kí tự không thường xuyên. BPR hoạt động trên mã Unicode chứ không phả byte sequences -> mô hình hóa mọi Unicode strings (base-vocabulary 130000). Điều này làm giới hạn vocabulary, vì vậy đê tránh được, ta ngăn BPE hợp nhất các danh mục kí tự cho bất kì chuỗi byte. Ta thêm 1 ngoại lệ cho spaces giúp cải thiện hiệu quả nén khi chỉ thêm minimal fragmentation từ nhiều multiple vocab tokens
-> Cho phép ta kết hợp lợi ích từ word-level LMS với tính tổng quát của byte-level. Vì vậy có thể gán xác xuất cho bất kì dãy Unicode nào
=> Có thể làm simple math

Model
Transformer cho LMs. Layer Norm (normalizaion) đặt tại đầu vào mỗi sub-block, vai trò như 1 pre-activation RNN và thêm 1 layer norm sau final self-attention block. 1 chút sửa đổi, residual path được dùng với model depth. Tỉ lệ trọn số của các lớp còn lại là 1/sqrt(N) (N là số residual layers).Vocabulary tăng lên 50257, context size từ 512 lên 1024 tokens và larger batchsize 512

Ta train với tập WebText. Nghiên cứu thêm task nữa về zero-shot. Từ khi hoạt động với byte-level thì giải quyết vấn đề mất dữ liệu và đa ngôn ngữ. Kết quả trên LM dataset thường là tỉ lệ hoặc lũy thừa của xác xuất trung bình âm (average negative log probability) của 1 đơn vị dự đoán chính tắc (canonical prediction unit) - character, byte hoặc word
Generalization vs Memorization
Để học task này, ta tạo Bloom filters chứa 8-grams của WebText training set tokens. Strings được normalized về lower-cased alphanumeric vứi 1 space như delimiter. Bloom filter được xây dựng sao cho tỉ lệ false positive cao hơn 1/10^8. Verified bằng cách tạo 1M strings, xem 0 có được tìm thấy vởi filter
-> Giúp tính toán
-> Khuyến nghị sử dụng khử trùng(de-duplication) n-gram overlap based như 1 bước xác minh quan trọng và kiểm tra độ chính xác trong quá trình tạo training và test splits cho các bộ dữ liệu NLP mới.



Có đến 175B parameters (hơn 100 lần GPT-2), tập trung vào các NLP tasks (translation, question-answering và cloze tasks)
Thực hiện tốt các task về zero-shot và few-shot. Có thể viết các bài viết dài hoàn hảo đến mức khó phân biệt với con người hoặc thực hiện các task chưa bao giờ được huấn luyện rõ ràng (few-shot learners)
Xu hướng pre-trained language và downstream. Càng ngày càng nhiều model sử dụng pre-trained recurrent hoặc transformer, sau đó trực tiếp fine-tuned, loại bỏ hoàn toàn về nhu cầu kiến trúc cho task-specific
Tuy nhiên, có một hạn chế chung là trong khi các architecture là task-agnostic, vẫn cần đến task-specific datasets và task-specific fine-tuning: để đạt được hiệu suất mạnh mẽ, ta phải tinh chỉnh rất nhiều trên tập dữ liệu các ví dụ cụ thể cho nhiệm vụ đó. Vậy mong muốn hiện tại là loại bỏ giới hạn này:
- Khó để thu thập 1 tập large supervised training dataset, đặc biệt là phải lặp lại mỗi task mới
- Tiềm năng khai thác các mối quan hệ giả (spurious correlations) trong training data đồng biến cùng tính cảm ứng (expressiveness) của model và độ hẹp (narrowness) của phân phối đào tạo. Điều này có thể tạo vấn đề đối với pre-training và fine-tuning: khi các models được thiết kế large cho quá trình pre-training, nhưng lại fine-tuned cho task có phân phối rất hẹp. Quan sát thấy rằng các larger models không nhất thiết tổng quát hóa out-of-distribution, cho nên còn tùy vào phân phối mà có thể không tốt với những mô hình bên ngoài nó. Do đó, hiệu suất được tinh chỉnh trên các điểm cụ thể, kể cả human-level, có thể phóng đại hiệu suất với các nhiệm vụ cơ bản (underlying task)


-> Meta-learning là tiềm năng giải quyết vấn đề này. Trong ngôn ngữ NLP, có nghĩa là phát triển 1 tập kĩ năng (set of skill) và khả năng nhận dạng (pattern recognition) trong training time, sau đó sử dụng khả năng đó tại thời điểm suy luận (inference time) để nhanh chóng thích ứng hoặc nhận dạng nhiệm vụ. Mà ở đây gọi là "in-context learning", sử dụng text input của 1 pre-trained language model như 1 form của task-specified: model dựa trên hướng dẫn tự nhiên và/hoặc 1 vài minh họa về task và sau đó được kì vọng hoàn thành các trường hợp tiếp theo bằng cách predict cái gì tiếp theo
Đối với parameter lớn, hầu như ô nhiễm dữ liệu (data contamination) không ảnh hưởng nhiều.
Ngoài ra, khi thử nghiệm với những model nhỏ hơn, cho thấy rằng hiệu suất tỉ lệ thuận với dung lượng mô hình, nên mô hình lớn hay meta-learners có tiềm năng hơn
Approach
Hầu như architect tương đồng với GPT-2. Cho nên ta chỉ phân tích những điểm khác nhau:
- Fine-tuning FT: updating weights of pre-trained model bằng cách training với supervised dataset specific với task chỉ định. Lợi ích chính của fine-tuning là strong performance trên nhiều benchmarks. Hạn chế chính là cần tập larger dataset mới cho mọi task, tập trung vào kém tổng quát hóa (poor generalization out-of-distribution) và khả năng khai thác tính năng giả (spurious features) của training data, có khả năng dẫn đến so sánh không công bằng với hiệu suất con người, -> không tinh chỉnh GPT-3 vì hướng về task-agnostic, về nguyên tắc thì đây là mục đích cho tương lai
- Few-Shot FS: model chỉ được cho một ít demonstrations của task tại inference time như điều kiện, nhưng không weight nào được cho phép updates. Ta đặt K (số examples) trong khoảng [10,100] vì model's context window (nctx = 2048). Lợi ích chính của few-shot là giảm lượng lớn yêu cầu cho task-specific data và giảm phân phối quá hẹp từ fine-tuning dataset. Hạn chế chính là kết quả vẫn còn khá tệ so với SOTA models. Dù vậy, một lượng nhỏ task specific data vẫn được yêu cầu -> Hay áp dụng cho các sự phân bố rộng rãi các nhiệm vụ (tức pre-training data) và nhanh chóng thích ứng task mới
- One-Shot 1S: giống few-shot nhưng chỉ 1 demonstrations. Lí do phân biệt 1S với FS và 0S là nó phù hợp nhất với một vài task về giao tiếp với con người (ví dụ tọa tập dataset dựa trên human worker service). Ngược lại, đôi khi khó giao tiếp bằng nội dung hoặc định dạng nếu không có ví dụ nào được đưa ra


GPT-3 được train với cỡ 45TB dataset trước filtering và 570GB sau filtering, khoảng cỡ 400B byte-pair-encoded tokens

Evaluation

- Với task free-form completion, ta dùng beam search giống GPT-2 (width = 4, length penalty của alpha = 0.6. Score bằng F1 similarity score, BLUE, hoặc exact match, tùy vào dataset)
Result
Với bộ dataset có 93% english, 7% ngôn ngữ khác, với task dịch:










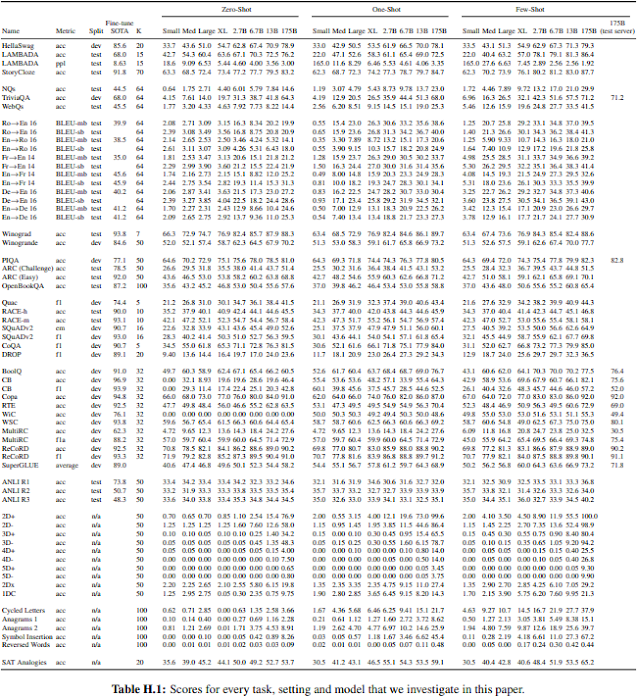
- Repeat semantically (lặp ngữ nghĩa) tại document-level (mất mạch lạc tại đoạn văn dài, tự mâu thuẫn, hoặc không theo trình tự)
- Poor sample efficiency during pre-training







Tham khảo
- https://trituenhantao.io/kien-thuc/hanh-trinh-cua-cac-mo-hinh-gpt-openai/
- https://huggingface.co/docs/transformers/model_doc/openai-gpt
- https://viblo.asia/p/bloom-filters-tai-sao-cac-mang-blockchain-lai-thuong-su-dung-no-GrLZD07eZk0
- https://arxiv.org/pdf/2005.14165.pdf (GPT-3)
- https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf (GPT-2)
- https://vnopenai.github.io/ai-doctor/nlp/vn-accent/n-grams/
Nhận xét
Đăng nhận xét