Mở đầu
Ta lấy ùn tắc giao thông làm ví dụ tham khảo, ta cần xây dựng 1 hệ thống kiểm soát giao thông thay cho các thuật toán truyền thống (sử dụng rule-base với green phase không dổi). Ta thử điều này với Reforcement Learning algorithm gọi là Deep Q-network (DQN)
- Có reward selection là 1 exponential function, dựa vào macroscopic fundamental diagram (MFD) dựa vào distribution
- Action là xác định traffic phase, dựa trên nhiều reward và các thông số độ đo
- Sau đó dùng phần mềm SUMO để kiểm tra độ hiệu quả
Thuật toán với adaptive reward mechanism đạt max 56384 vehicles
=> Việc sử dụng MFD là 1 hướng đi tốt
Tại sao các thuật toán truyền thống với độ dài các phase luôn cố định không hoạt động tốt với các chỗ đông dân? -> Vì phân phối không đồng đều
Idea
Max-pressure approach so sánh sự thay đổi áp suất (pressure) giữa các nhánh (arms) tại giao lộ (intersection). Việc chỉ xem xét hàng đợi liền kề tại mỗi ngã tư, vậy đây là cách tiếp cận phi tập trung. Ngoài ra, ngoài max-pressure, ta không cần biết về nhu cầu giao thông (traffic demand) -> không cần retiming procedure
-> Kết hợp max-pressure với MFD assessment
Lấy điều kiện giao thông (traffic conditions) làm trạng thái (states) và cấu hình tín hiệu (signal configurations) làm hành động (action)
Mục tiêu của tác nhân RL phi tập trung (decentralized RL agents) là minimize pressure để cân bằng vehicle distribution và maximize thông lượng (throughput)
Dùng intersections như self-learning agents cũng là 1 cách hiệu quả vì không phụ thuộc vào supervised learning labels. Đặc tính của RL là cho phép agents update signal cho new observations, vì vậy có thể thay thế chuyên gia con người bằng online learning và trial-and-error interaction
-> Q-Learning là Deep learning methods combined vào RL, tức sử dụng data structure để học relationship giữa states và actions. Q-Learning là 1 phương pháp không mô hình(model-free), không chính sách (off-policy), khác biệt thời gian (temporal difference) tìm kiếm bộ action tốt nhất dựa trên state (sort out problems with stochastic transitions and rewards without requiring adaption)
Deep reinforcement learning (DRL) has been used to control intersections via the deep-Q-network (DQN) by utilizing a neural network to approximate the Q value function
Ta lấy pressure làm reward -> max-pressure dùng greedy algorithm để minimize pressure, tương tự với throughput
Large-scale traffic signal control: áp dụng 2 multi-agent reinforcement learning (MARL) algorithms mới, Nash-A2C và Nash-3AC. Tức kết hợp cân bằng Nash vào kiến trúc actor-critic (diễn viên - phê bình)
-> Reward thành long-term trafic conditions (waiting time). Trong bài này thì dựa trên traffic stream properties (luồng flow và tỉ trọng desity), nhằm cải thiện model khi lưu lượng traffic conditions vượt quá điều kiện dòng bão hòa saturation flow condition
=> Giải pháp dựa vào cấp số nhân, xây dựng reward có thể xử lí tắc nghẽn trong mọi kịch bản, thay vì ngăn ngừa tắc nghẽn
Phương pháp MFD được sử dụng để kiểm tra hiệu suất theo cách vĩ mô (tổng thể) hơn là phân tích kết quả tại mỗi nút. Reward ưu tiên pressure cho kết quả tốt trước khi đến điểm bảo hòa (saturation flow), trong khi reward ưu tiên queue length có kết quả tốt hơn tại điểm bảo hòa -> Vì vậy sử dụng hàm mũ (exponential function) để kết hợp tổng pressure và tổng queue length tại mọi điểm
Vậy ta cần:
- Thiết kế algorithm, RL-based với MFD để kiểm soát hiệu quả trong các điều kiện lưu lượng khác nhau
- Multi-agent DQN sử dụng để ước lượng Q-value để quyết định action thực hiện bởi agent tại mỗi intersection
- Adaptive reward function (exponential approach) kết hợp pressure và queue length của phase tại mỗi intersection
- Bộ điều khiển (developed controller) để ngăn luồng bị kẹt hoàn toàn (gridlock) và tăng số lượng phương tiện (maximum throughput)
Problem Formulation
Traffic Network
Ta hình dung có các intersections (giao lộ) và các edge (cạnh), các vehicles vào các edge nodes và đi thẳng, rẽ trái hoặc rẽ phải dựa vào road directions (hmm graph?)

Số làn xe của 1 đường = số vehicles có thể đi qua đồng thời. Một số hướng di chuyển có thể được kích hoạt đồng thời. Một giai đoạn giao thông là kết hợp nhiều chuyển động định hướng cùng lúc nhwung chỉ có 1 giai đoạn lưu lượng có thể hoạt động tại một thời điểm. Một chu kì giao thông là tập các giai đoạn lưu lượng được kích hoạt liên tiếp. Các giai đoạn không được kích hoạt tuần tự (sequentially) (Non-cyclical systems)
Với large-scale traffic control system, các intersection tác động nhau, làm bài toán phức tạp hơn. Ta gọi tối ưu 1 nút là locally optimal solutions, đánh giá bằng level of service (LOS)
Max-pressure Control
Quản lí các intersection bằng cách kích hoạt traffic phase với highest pressure. Có 2 cách:
- cycle-based scheme
- slot-based scheme (không dùng specific sequence pattern)
Traffic phase pressure (Pp) định nghĩa là khác biệt số vehicle trong phase tại upstream và downstream

Việc phân bổ green time cho mỗi arm trong cycle-based methods phải tỉ lệ thuận pressure weight
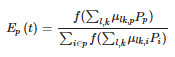


Là phương pháp sử dụng để xác định cycle length lí tưởng cho mỗi phase tại mỗi junction (điểm nối). Tính toán traffic asuming tại trạng thái ổn định (có thể áp dụng cho thời gian cố đinh fixed-time và vehicle-actuation), quản lí các intersections bằng phát triển cycle-based control scheme. Webster algorithm tối ưu cycle length C bằng critical flow data Yi và lost time trong 1 cycle Lt với N là số intersection:


Macroscopic Fundamental Diagram
Việc phân tích và đánh giá traffic control strategy được thực hiện đồng bộ trên toàn bộ model (cấp vĩ mô macroscopic evalation) để tối ưu toàn cục. Ta chọn MFD là công cụ phân tích vĩ mô để mô tả quan hệ giữa average traffic flow trong mỗi lane (Ft) và average traffic density trong toàn model (Kt):


Reinforcement learning in Traffic Control
RL có thể học thông qua trial-and-error với các giả định random của traffic model. RL là cần thiết vì hoàn cảnh giao thông ngày càng thay đổi và phức tạp, do đó cần 1 giải pháp có thể tự phát triển (dựa trên phản hồi thu được dưới dạng nhiều thông tin khác nhau). Thông tin về traffic conditions làm cơ sở cho agents chọn 1 action
Reinforcement Learning
Theo hướng Markov decision process (MDP) biểu diễn bởi 1 bộ (S, A, P, R, gamma) ứng trạng thái states, hành động action, xác xuất chuyển đổi transition probabilities, phần thưởng rewards và hệ số chiết khấu discount factor. Phân phối xác suất P(s′,r|s,a) có action a∈A(s) với mọi state s∈S đưa ra state mới s' và reward r∈R. 1 chính sách (policy) π(a|s) đối với MDP là ánh xạ mọi s∈S thành phân phối xác suất trên A(s), khi state-value function Vπ(s) xác định reward tại bắt đầu s tuân thủ π(.|s) được định nghĩa là:
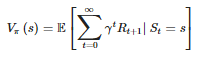
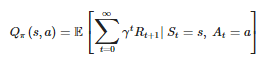
và action-value function Q∗π được định nghĩa:
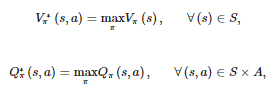

Deep Q-network (DQN) là value-based reinforcement learning algorithm dùng deep neural network Qθ để xấp xỉ Q∗. Nhận state s là input và estimate Q-value cho action a như output (ánh xạ đến từng action cụ thể, dựa trên action value). Thay vì dùng kết quả cuối cùng để update Q-function, DQN lưu trữ quá trình transtion dưới dạng (St,At,Rt,St+1), sau đó dùng 1 mini-batch để sample uniformly random, để train parameters bằng stochastic gradient descent. DQN dùng replay memory để hạn chế học từ các trải nghiệm kết nối với nhau và cho phép học lại từ trải nghiệm trước đó
DQN có 2 neural network riêng biệt:
- Target neural network Qθ¯ tính rt+γmaxut+1Qθ¯(s′,a′)
- Online neural network Qθ: estimate Qθ(st,at)
Vì vậy loss function để update paramaters của online network Qθ là:

Về bản chất,mục tiêu DQN là khớp estimated Q-value với target chính xác hơn
Phương pháp thăm dò ϵ-greedy exploration thường được dùng để tìm policy mới mỗi iteration (1 action được chọn random cho mọi state s với probability ϵ). Nếu probability = 1 - ϵ thì max Qt được chọn. Cách khác là Boltzmann exploration, xác định action dựa trên Boltzmann distribution (softmax) và Q-value thu được, ảnh hưởng bởi temperature parameter τ(mô tả tính chủ động của 1 action). Khi temperature lớn hơn (τ→∞) tất cả action có cùng probality, trong khi temperature thấp hơn (τ→0), probability với max Q-value gần = 1

Action cần chọn có softmax function lớn nhất. Lợi thế của Boltzmann so với ϵ-greedy là thông tin tiềm năng (potential value) ở các hành động thay thế (alternative actions) cũng có thể được xem xét
Agent Design
State: gồm 4 traffic feature cho mỗi intersection, cụ thể là 1 array biểu thị currently active green phase, 1 binary variable thể hiện min green time trong current phase đã qua chưa, mật độ phương tiện đến (density of incoming) tại mỗi phase. Density và quêu length được định nghĩa cho mỗi phase để hỗ trợ agent chọn action
Action: dạng phase selection tại mỗi intersection. Trong network, mỗi intersection có số phase khác nhau, agent sẽ đánh giá hiệu xuất của action sau mỗi 5s và có thể chọn action khác (selected action có max duration là 25s)
Reward: dựa vào max-pressure, định lượng của upstream và downstream pressure tại 1 intersection. Reward ri:
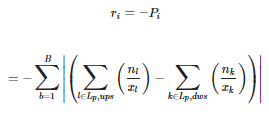

Implementation
Traffic Control Using the Max-Pressure Algorithm
Max-pressure hiện là 1 trong SOTA của traffic control. 1 slot-based max-pressure đã dduwcoj dùng, hoạt động bằng cách kích hoạt phase có highest pressure value. Max-pressure Equation, phù hợp cho intersections có độ dài tương đối bằng nhau tại mỗi phase (similar road capacity). Tuy nhiên, khi length thay đổi trong mỗi phase varies,dựa trên trafic network conditions, phương trinh này ít đại diện cho thực tế hơn:


Traffic Control Using Reinforcement Learning
Multi-agent DQN được chọn vì khả năng thay đổi cao về số lượng states, gồm số action và intersections, mỗi intersection điều hành bởi 1 agent duy nhất.












Tham khảo
Nhận xét
Đăng nhận xét