So với COLMAP, SuperGlue+Superpoint có thể đưa vào pipeline rộng hơn, khả năng chịu được trong sự thay đổi lớn viewpoint hơn, mạnh với việc thay đổi ánh sáng và cắt 1 phàn ảnh. Đồng thời phối hợp trong dense multi-image fusion và loop closure detection
Với sự liên quan cực dài, từ BERT, Transformer, GNN, NLP, Superpoint và CV, ta thấy model này được áp dụng rất phổ biến và tổng hợp từ nhiều yếu tố -> bài này dài :))Transformer (2017)
Ra đời 2017 bởi Google với mục đích ban đầu là thay thế RNN models (ví dụ LSTM)
Nổi nhất là BERT (Bidirectional Encoder Representations from Transformers) và GPT (Generative Pre-trained Transformer, core của ChatGPT), mà có thể fine-tuned sang 1 task khác.
Chi tiết algorithm: Transformer vẫn giữ attention mechanism nhưng không có recurrent structure. Tức tạo đề xuất rằng, với đủ trainning data, atention mechanism có thể một mình đạt đến mục đích cảu RNNs+attention
Sequential Processing
Việc tính token n dựa vào n-1 state trước đó rất khó khăn, dễ dẫn đến vanish gradient, tiêu tốn nhiều khả năng tính toán nhưng lợi ích không hiệu quả cho RNNs
Residual
Xem lại ResNet (https://hoanglong187.blogspot.com/2023/01/0-tom-tat-lien-quan-cac-models.html)
Self-Attention
Các vấn đề trên hầu hết đều đã giải quyết bởi attention machanism, giúp model có thể rút ra và thêm vào tại bất cứ điểm nào trên sequence, thậm chí mang thông tin ở các token xa
Input
Input text được parsed thành các tokens (byte pair encoding tokenizer). Mỗi token corvert 1 word embedding + positional information thành 1 vector
Encoder-decoder architecture
- Encoder: chuyển input thành các feature learning có khả năng học tập cảu task. Đối với Neural network là các hidden layer (Conv + Maxpooling với CNN và Embedding + Recurrent với RNN)
- Decoder: đầu ra Encoder là đầu vào Decoder. Mục đích tìm phân phối xác xuất các features learning ở Encoder -> xác định nhãn. Output là 1 nhãn (với classificate) hoặc 1 chuỗi các nhãn (với seq2seq)
seq2seq model: LSTM xử lí và lưu dữ liệu vào các sell state. Đầu ra của Encode là 2 vector (cell state C và hidden state h), 2 vector này là init_state của lớp đầu tiên của decoder, decoder sẽ tính toán và sinh chuỗi tử 2 vetor trạng thái. Nhìn chung, Encode-Decode được triển khai bằng nhiều lướp RNN/LSTM
Thuật toán: feed-forward neural network + residual để kết giao + normalizationencoder generate (sinh) encoding chứa thông tin về 1 phần input liên quan những phần khác -> đưa làm input cho encoder layer tiếp theo. Decoder ngược lại, lấy mọi encodings và thông tin ngữ cảnh để ra output sequence. Tức cả encoder và decoder vừa làm attention mechanism
Với mỗi part, có attention weihts ảnh hưởng các part khác. Mỗi decoder layer có thêm attention mechanism từ decoder trước, trước khi nhận thông tin từ encoding
Cơ chế Attension
Scaled dot-product attention
Là phần transformer building block. Khi 1 sentence đi vào transformer model, attention weights được tính giữa mỗi token. Attention unit nhúng mọi token mà chứa thông tin bản thân cùng với weighted combination gập từ các token liên quan, từ đó tạo nên attention weight
Với mỗi attention unit, transformer học 3 weight matrices: query weight Wq, key weights Wk và value weights Wv
Multi-head attention
Mỗi tập (Wq, Wk, Wv) gọi là attention head, mỗi layer trong transformer có nhiều tập attention head. Chúng ta có thể có một định nghĩa khác về "liên quan". Ngoài ra, số trường hợp ảnh hưởng nên được giảm dần theo thời gian. Transformer attention có rất nhiều lợi ích, ví dụ tập trung ở verb hay objects. Các phép tính có khả năng thực hiện song song, với output là cho feed-forward neural network layers
Encoder
- Mỗi Encoder có 2 components chính: self-attention mechanism và feed-forward neural network. Self-attention biến input encoding từ encoder trước và weights liên quan thành output encoding. Feed-forward NN xử lí từng output encoding riêng lẻ. Sau đó các output encoding này đến encoder tiếp theo như input hoặc đến decoders
- Encoder đầu tiên lấy thông tin vị trí (xắp sếp) và ambeddings của input sequence làm input
- Encoder là bidirectional ( 2 chiều). Attention có thể đặt trước hoặc sau token. Ta dùng token thay vì word để tránh polysemy (đa nghĩa)
Positional encoding
Điều này giúp transformer lấy bất kì encoded position nào và tính linear sum của encoded locations xong quanh. Tổng này, kết hợp với attention machanism là attention weight xung quanh. " Chúng tôi giả thiết rằng nó cho phép mô hình dễ dàng học tham dự từ vị trí tương đối"Decoder
- Mỗi decoder có 3 component chính: self-attention mechanism, attention mechanism từ encoding và feed-forward neural network. Cấu trúc gần giống encoder, những thêm attention mechanism được chèn vào các thông tin liên quan từ encoding tạo bởi encoders (encoder-decoder attention)
- Tương tự encoder đầu, decoder đầu cũng lấy thông tin vị trí và embedding của output sequence như input. Transformer không thể dùng hiện tại hay tương lai output để predict 1 output, vì vậy output sequence cần bị che 1 phần để ngăn luồng thông tin đảo ngược này. Cho phép tạo văn bản tự hồi quy (autoregressive text generation). Với mọi attention heads, không thể đặt phía sau tokens. Theo sau decoder cuối là 1 final linear transformation và softmax layer, để tạo output probabilities
GPT có decoder-only architecture
Tóm tắt:
sequence of tokens -(embedding layer)-> embedded tokens -(multi-head self-attention)-> weight the contribution -(feed-forward neural network)-> -multi-head self-attention stack of layer, repeat multiple time (Transformer Encoder))->-(linear layer + softmax ativation)->predict/classificate
Implement
Soft and Hard Attention
Thường áp dụng cho task tạo caption ảnh
Đầu tiên được xử lí với CNN để trích xuất đặc trưng -> LSTM kết hợp attention decode các đặc trưng đó để tạo caption. Chi tiết hơn:
- Soft attention: sử dụng attention như trọng số để tính context vector và nó là hàm khả vi nên có thể dùng gradient decense kết hợp backporopagation để huấn luyện. Tuy nhiên chí phí tính toán tốn kém
- Hard attention: thay vì tính trung bình trọng số của mọi vector trạng thái ẩn thì có thể sử dụng attention score để chọn vị trí vector ẩn thích hợp nhất. Hard attention thường được huấn luyện qua Reinforcement Learning. Chi phí tính toán thấp hơn nhưng kĩ thuật phức tạp hơn
Global and Local Attention
với seq2seq ta mặc định attention tính toán dựa trên toàn bộ input (global attention). Tuy nhiên nhiều lúc không cần thiết -> local attention: chỉ quan tâm 1 phần đầu vào, có thể coi như hard attention. Vậy global attention giống fully connected, còn local attention giống convolution
Graph Neural Network (GNN)
Graph Theory: gồm vertice (node) và edge. Thường được kí hiệu G=(V,E)
Thường được biểu diễn bởi 1 Adjacency matrix A NxN (ma trận kề/ ma trận biểu diễn các node nào nối với nhau 0 là không nối, 1 là có). Nếu mỗi node có F features, vậy matrix có dimension là NxF
Vì sao Graph khó phân tích?
1. Không phải coordinate systems như Euclidean space (waves, images) hay time-series signals (time, text) mà có thể dạng 2D hay 3D
2. Không có form cố định
3. Khó tưởng tượng hoàn toàn (với graph lớn)
Vì sao dùng Graph?
1. Hướng tốt cho biểu diễn các quan hệ, tương tác, giao thoa
2. Có thể giải quyết các vấn đề phức tạp bằng cách đơn giản hóa / biến đổi
3. Graph Theory
Thường dùng cho 2 bài toán chính:
- Cho 1 graph G, predict label F của G
- Cho 1 graph G và note v(hoặc cặp nodes (u,v)), predict node f(v)/f(u,v)
Graph truyền thống thường gặp:
1. Searching algorithm: BFS, DFS, Level Search, ...
2. Shortest path algorithm: Dijkstra's algorithm, Nearest Neighbour
3. spanning-tree algorithms: Prim's algorithm
4. Clustering methods: Highly Connected Components, K-mean
Không có cách để biểu diễn graph level classification
Có 3 lại chính:
- Recurrent Graph Neural Network
- Spatial Convolutional Network
- Spectral Convolutional Network
Thông tin thường dựa vào concept như hàng xóm (các node xung quanh) và các mối liên hệ
Tức, nếu ta có mọi node là 1 state, ta có thể dùng node state (x) để tính output (o), dựa vào concept. Final state (x_n) của node gọi là node embedding. Mục đích của mọi GNN là xác định node embedding của từng node, dựa vào thông tin và các node xung quanh
Mục đích chính: thêm tính "logic" vào pipeline của các mô hình learning
Recurrent Graph Neural Network RecGNN
Là loại GNN phổ biến nhất
Xây dựng dựa vào giả thiết Banach Fixed-Point Theorem: (X,d) là 1 complete metrix space, (T:X -> X) là 1 contraction mapping (ánh xạ co) ( d(f(x), f(y)) <= kd(x,y) với d là distance Euclide). Thì T có 1 fixed point duy nhât (x*) mà với mọi x thuộc X, sequence T_n(x) khi n -> +infinity hội tụ về (x*). Tức nếu dùng mapping T cho x k lần thì x^k có thể = x^k-1RecGNN định nghĩa 1 function f_w:
Final node state o_n được dùng để làm ra output để make decision mỗi nodeSpatial Convolutional Network Xây dựng tương tự CNN trong task image classification và segmentation.
Ý tưởng của convolution trong 1 image là tổng các pixel xung quanh center pixel, filter với parameterized size và learnable weight. Spatial Convolutional Network cũng có ý tưởng như thế, tức là tổng hợp các feature từ các node xung quanh về center node
Spectral Convolutional Network
Xây dựng trong graph signal preocessing theory, phức tạp nhất
Có thể hiểu cơ bản là:
Sau đó là 2 layered neural network structure
Với A_head là
pre-processed Laplacian của
graph adjacency matrix A (tức
Laplacian matrix L = D - A với D là
degree matrix (matrix đường chéo với mỗi ô là degree của node) -> pre-processed Laplacian là 1 bản nhỏ hơn, ví dụ normalized Laplacian L_norm = D^(-1/2) * L * D^(-1/2) sử dụng trong Spectral Clustering)
Vậy biểu thức bên trên đơn giản là 2 fully-connected layer structure,
ta giải thích tại sao nó ứng hình dưới:
ta có Adjacency matrix (A) 4x4 (có thêm đường chéo 1 để feature aggregation) và Feature matrix (X) 4x3
Vậy A x X = H là tổng hợp các features của nodes mà hiện nối với node đang xét
Vậy, Spectral Convolutional Network và Spatial Convolutional Network mặc dù từ basis khác nhau nhưng cùng propagation rule
Nhìn chung, mọi convolutional graph neural networks cùng 1 format là học 1 function để thông qua thông tin các node xung quanh mà update node state hiện tại bằng message passing process
- Node Classification: predict node embedding với mọi node. Thường được train với semi-supervised khi 1 phần graph được label. Ví dụ: citation networks, Reddit posts, Youtube videos, hoặc Facebook friends relationships
- Link Prediction: task là hiểu liên kết giữa các đối tượng và predict xem 2 đối tượng có liên kết. Ví dụ: Recommender system
- Graph Classification: classify cả graph thành nhiều categories, giống với image classification nhưng là phân loại cấu trúc
Trong NLP: GNN sử dụng trong quan hệ giữa các từ hoặc tài liệu để predict categories. Ví dụ: citation network -> phân loại tài liệu
Trong CV:
- Sau bước object detection, chúng ta tìm liên hệ giữa các object bằng GNN, để xác định vị trí tương đối trong 3D
- Hoặc một ứng dụng khác là image generation từ graph desriptor. Ví dụ: text2image: GAN, autoencoder. Thay vì sử dụng text cho image description, ta sinh thêm thông tin từ sematic structure.
- zero shot learning (ZSL), học từ không sample, học cách suy nghĩ theo logic
Là khó khi tìm liên hệ qua text descriptor nhưng có thể corvert sang dạng graph
Message Passing Paradigm
Hay Message Passing Graph Neural Network MP-GNN
Cập nhật node dựa vào tổng hợp của các node kề nó.
Giả sử hv(t) là giá trị node embeddings cho 1 vài vertex(node) v tại thời điểm t, ta có 3 bước:
- Initialization: chọn giá trị cho mọi đỉnh (vertex) - Aggregation: + Gồm Message calculation: tính số thông tin đến các node kề dựa vào biểu diễn của nó và biểu diễn của các node kề (ví dụ như nếu coi các node là các image thì thông tin là các point pairs). -> cần 1 neural network + Message aggregation: Tổng hợp thông tin nhận từ các node kề thành 1 biểu diễn duy nhất -> aggregation method: mean hoặc max pooling
- Transformation: Dùng 1 neural network để cập nhật node
Vậy ta có tập Compact:-> Các trạng thái tiến về 1 điểm tụ Ví dụ: - Với Semi-Supervised Classification with Graph Convolutional Networks ta có thể dùng 1 mean Multi-layer Perceptron (MLP): - Hoặc ta có thể dùng 1 tổng summation và 1 MLP: Feed Forward Neural Network
Thông tin đi theo 1 chiều từ input -> output, không loop hay Cycle, sau đó estimate result mà chỉnh lại weight giữa các layer
Backpropagation: tính gradient của loss function theo weight đã chạy, tính dradient của 1 layer tại 1 thời gian, rồi update weight theo hướng ngược lại gradient
Cách áp dụng SuperGlue
Đối với việc sử dụng Deep Learning, có các vấn đề nảy sinh với các tập hợp như point cloud hay thiết kế hàm bất biến/ hàm hoán vị bằng cách tổng hợp thông tin giữa các phần tử. Một số phương pháp chọn coi mọi phần tử như nhau rồi global pooling hoặc instance normalization (chuẩn hóa cá thể), trong khi số khác chọn local neighborhood.
Attention có thể vừa thể hiện tính tổng hợp global và tổng hợp local bằng cách focus vào một số tính chất cụ thể, do đó linh hoạt hơn. Self-attention có thể xem tập hợp này là ví dụ của Message Passing Graph Neural Network trong 1 complete graph, ta áp dụng attention vào nhiều loại edge khác nhau, và SuperGlue để suy luận về tính liên kết giữa 2 tập local feauture
SuperGlue Architecture
Chúng ta có những tính chất:
- 1 keypoint chỉ có thể tương ứng <= 1 point tại image khác
- 1 vài keypoint sẽ không có pair tương ứng
-> SuperGLUE tập trung vào tìm 1 hình chiếu cụ thể của cùng 3D points và xác định các outliers
Sau task Feature Extract, ta có các keypoint positions p và visual descriptor d -> ta coi đó là 1 bộ local features (p,d) (trong p có cả confidence c (pi := (x, y, c)i))
Ta extract d bằng Superpoint (CNN) hoặc SIFT (traditionals descriptors) -> có 2 tập A, B là tập các local features của 2 ảnh
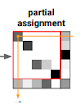
Ta định nghĩa Partial Asignment P thuộc [0,1]MxN: P1N < 1M và Pt1M < 1N. Mục đích chúng ta là predict P từ 2 tập local features 1. Attentional Graph Neural NetworkNgoài trư xét vị trí của các keypoint, kết hợp thêm ngoại cảnh có thể làm tăng sự khác biệt. Tường minh hơn, khi con người so sánh 2 ảnh, chúng ta nhìn qua nhìn lại 2 ảnh, không chỉ tìm vị trí mà còn ngoại cảnh. Ta đặt block đầu tiên của SuperGLUE là Attentional Graph Neural Network. Nó tính các matching descriptor fi bằng cách để feature giao tiếp với nhau
-> long-range feature aggregation để đảm bảo các kết nối dài
Keypoint Encoder: ta embedding keypoint thành 1 high-dimensional vector bằng Multi Layer Perceptron(MLP) bằng cả vị trí và descriptorMultiplex Graph Neural Network: ta xây 1 complete graph với các node là keypoints ủa mỗi image. Graph có 2 loại undirected edge (nên gọi là multiplex graph). - Intra-image edges/ self edges (epsilon self) nối keypoint i với mọi keypoints chung image.
- Inter-image edges/ cross edges(epsilon cross) nối keypoint i với mọi keypoints khác image.
Ta dùng message passing formulation để truyền thông tin theo 2 loại cạnh.
Multiplex Graph Neural Network bắt đầu với high-dimenssional state tại mỗi node và tính toán lại tại mỗi layer một cập nhật tương ứng thông tin tổng hợp đi qua mọi cạnh tương ứng của mọi node
Giả sử (l)XiA là biểu diễn của i trong image A tại layer l. Message m(epsilon->i) là kết quả tổng hợp từ mọi keypoints. Ta có residual message update:Với [.||.] là concatenation. Để có tính cân bằng, từ l =1, epsilon = epsilon-self nếu l lẻ, và = epsilon-cross nếu l chẵnAttention Aggregation: Self edges dựa vào self-attention và cross edges dựa vào cross-attention. Dựa vào query qi, value vj và key kj. Ta cps công thức tính message như 1 tỉ trọng trung bình:Với attention weight alphaij là Softmax của key-queryGiả thiết keypoint i thuộc image Q và toàn bộ keypoint nguồn thuộc image S (Q,S thuộc {A, B}^2) thì: Mỗi layer l có parameter riêng, học và chia sẻ với mọi keypoints ở mỗi ảnh. Đồng thời, ta cải thiện thêm với multi-head attention. Vì vẫn giữ được giá trị về vị trí trong encode, mô hình tăng tính tập trung cho các keypoint gần nhau và đối chiếu tương ứng với vị trí các pairs. Từ đó có thể biểu diễn các phép biến đổi hình học và phép gán. Do vậy, Final mathing descriptor có thể coi là linear projections:Tương tự với image B
2. Optimal matching layer
Block lớn thứ 2 của SuperGlue là optimal matching layer, để tạo partial assignment matrix P. Tức ta cần maximizing hàm score matrix
S thuộc R[MxN], điều này tương ứng linear assignment problem
Score Prediction: xây dựng biểu diễn phân biệt của mọi M x N matches bằng cách pairwise score của descriptors của chúng:Với <.,.> là inner product (dot product). Để học visual descriptors, matching descriptor sẽ không normalized và giá trị có thể đổi trong quá trình training Occlusion and Visibility: Để có khả năng xóa một vài keypoint, ta thêm 1 tập dustbin (thùng rác) để các keypoint chưa được nối có thể nối vào đó. (dustbin cũng đã được sử dụng ở Superpoint để chứa các image cells không có detection). Ta cải thiện S thành S_ bằng thêm row mới và column mới (point_to_bin và bin_to_bin score) với 1 giá trị duy nhấtMỗi keypoint trong A chỉ nối 1 keypoint ở B, nhưng dustbin có thể có nhiều matches như nó đang trong 1 tập hoàn toàn khác:Sinkhorn Algorithm: Bài toán trở thành optimal transport giữa phân phối rời rạc a và b với scores S_. Được giải quyết qua exp(S_) và Softmax. Sau T iterations, ta bỏ dustbins và lấy P = P_[1:M, 1:N]
Thuật toán Sinkhorn nói rằng mọi ma trận vuông dương đều có thể chuẩn hóa (biến thành doubly stochastic matrix D1AD2 ) (Stochastic process)
3. Loss Cả graph neural network và optimal matching layer đều có đạo hàm -> Cho phép back propagation. SuperGlue được train với supervised, cho phép gán nhãn unmatched. Vậy ta cần minimize negative log-likelihood của asignment P:-> Mục đích là maximizing precision và recall của matching
Bởi vì kết quả của SuperGlue rất tốt (> 98%) nên thường đi với Direct Linear Transform (DLT giống giải hệ phương trình) thay vì RANSAC cho task homography estimation (vì RANSAC chọn random giống Random Forest)-> Mỗi phần đều quan trọngImplementsource: https://github.com/magicleap/SuperGluePretrainedNetwork/blob/master/models/superglue.py Tham khảo
- https://arxiv.org/pdf/1911.11763.pdf
- https://github.com/magicleap/SuperGluePretrainedNetwork
- https://en.wikipedia.org/wiki/Word_embedding
- https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
- https://pytorch.org/tutorials/beginner/transformer_tutorial.html
- https://towardsdatascience.com/an-introduction-to-graph-neural-network-gnn-for-analysing-structured-data-afce79f4cfdc
- https://graph-neural-networks.github.io/static/file/chapter20.pdf
- https://github.com/phamdinhkhanh/phamdinhkhanh.github.io/blob/master/_posts/2019-06-18-AttentionLayer.md
- https://arxiv.org/pdf/1706.03762.pdf
- - https://github.com/phamdinhkhanh/phamdinhkhanh.github.io/blob/master/_posts/2019-06-18-AttentionLayer.md
- https://wandb.ai/graph-neural-networks/spatial/reports/An-Introduction-to-Message-Passing-Graph-Neural-Networks-GNNs---VmlldzoyMDI2NTg2
- https://github.com/magicleap/SuperGluePretrainedNetwork/blob/master/models/superglue.py
- https://en.wikipedia.org/wiki/Sinkhorn's_theorem































Nhận xét
Đăng nhận xét